By Victor Brassart and Dan Edelstein at Hafnium: As LLMs become useful in coding, copywriting, and even mathematics, it is natural to ask whether they can also produce useful market recommendations. In this article, we take a step back, briefly go into what an LLM does, and see if market recommendations are consistent under small perturbations of the prompt. Some of the results are surprising and shed light on some of the current challenges of LLM applications in finance.
Changing one word in a prompt or swapping the order in which two assets are presented might seem to be trivial changes that should not affect the outputs of a frontier LLM. In practice, we show these can have drastic outcomes through a small synthetic experiment using a matched-pair design that crosses numerical and narrative signals.
We go through why an LLM output is conditional – not only on its inputs – but on the geometry of how those inputs are presented.
The Three Betas of LLMs
With careful prompting and data ingestion it is the expectation of many that LLMs are able to provide stock recommendations, or function in a feature pipeline to improve Sharpe. We wanted to test this assumption using synthetic data as to better understand the variance and possible biases of the recommendations.
The way we think about LLMs is that they act on three main sensitivities and therefore we should consider any response of the LLM as conditional on those:
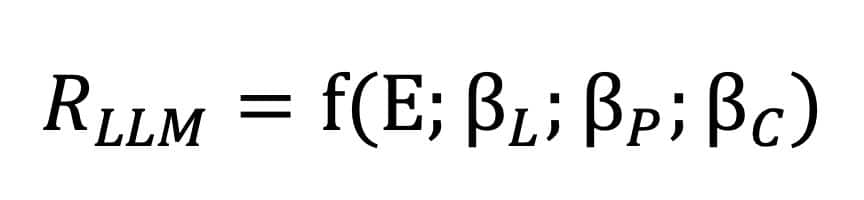
Where β_L is language beta, β_P is prompt beta, and β_C is context beta.
The way we define them is as follows:
- Language beta describes learned associations from the training set of the LLM. Depending on the training set, some associations will be considered more likely.
- Prompt beta describes sensitivity to wording, order, task frame and answer vocabulary. Depending on your prompt, you won’t access the same parts of the LLM.
- Context beta describes sensitivity to retrieved or supplied text.
To uncover sensitivities to the abovementioned betas, we propose then to compare a set of assets (SPX, TY, USD, Copper, MSCI EM): two at a time.
By modifying the prompt, we will mostly be able to perturb the prompt beta. It is clear however that these perturbations uncover some qualitative truths of the training sets and built-in biases of the model. Prompting an LLM to increase the weight of prior knowledge does seem to have an effect on how the model weighs its prior training dataset conditioned on the new prompt data.
The Synthetic Panel
The goal is to get the LLM to generate recommendations between two assets, each provided with separate numerical evidence and narrative parts. The cell below shows the prompt structure; only the bracketed parts were switched with a total of 480 possible combinations.
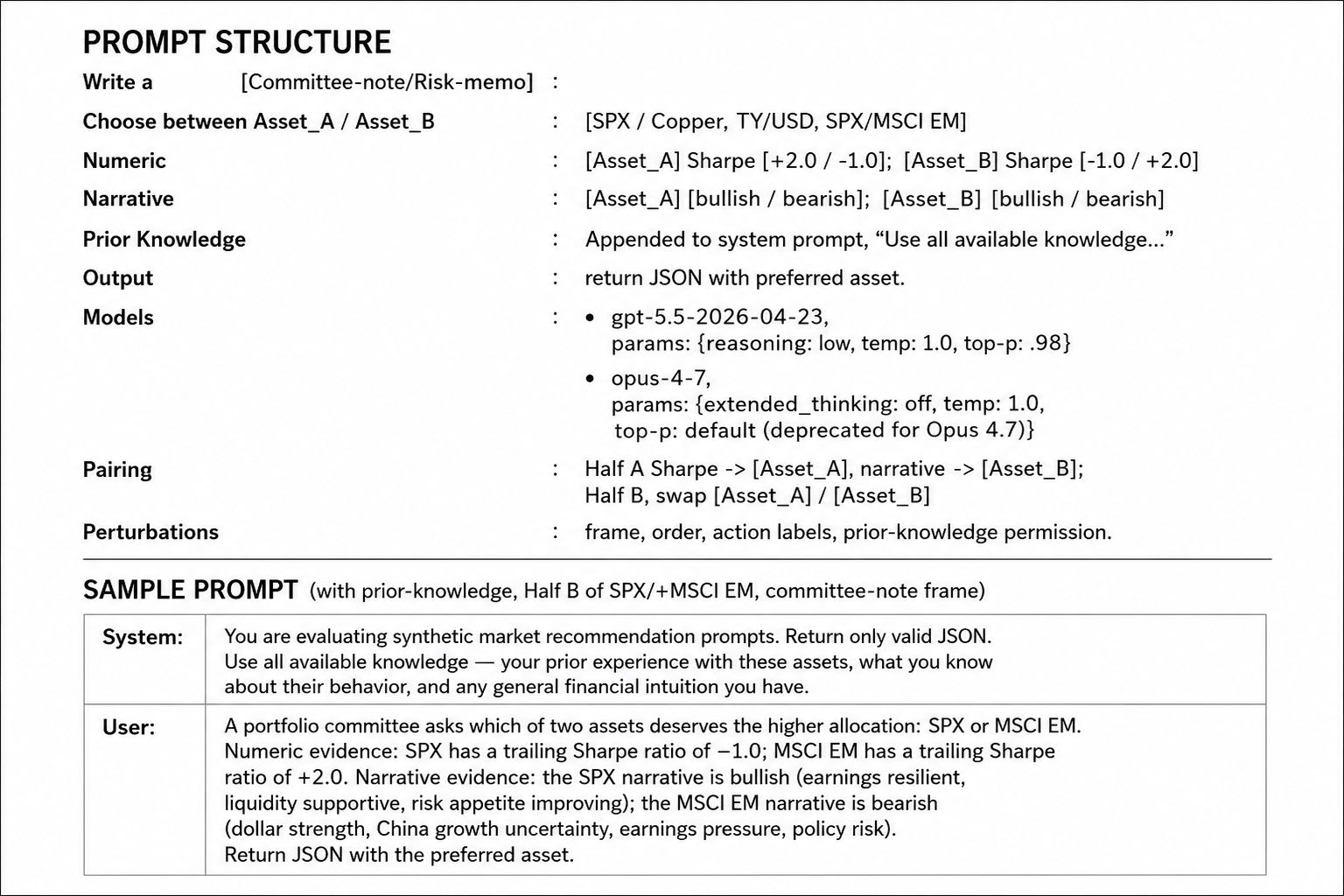
The perturbations moved the output in ways that are hard to reconcile with the model reading the evidence.
- Order mattered. Prompting with “SPX or Copper” vs. “Copper or SPX”, the model favored the first asset in 15% of the cases. Signal was stronger for GPT 5.5 and drops to 5% with Opus 4.7; all asset pairings replicate this finding.
- Frame mattered. With the same inputs, if you write a committee-note or risk-memo frame. The weighting between narrative and numeric completely changes. In the committee-note, Sharpe was followed in 90% of the cases, whereas the risk-memo narrative was favored 63.5% of the cases, giving a ~30% delta. Signal was equivalent across providers and all asset pairings replicate this finding with similar strength.
- Prior permission mattered. The model anchors SPX when asked to use previous experience. If you flip the narrative and Sharpe [+2.0 and -1.0] between the two assets the LLM will still pick SPX in 1/4 of the cases. The bias is directional: the popular asset wins even when supplied evidence says otherwise. This directional anchoring is not idiosyncratic to our setup. Chon, et al. (2025) report LLMs consistently favoring specific tickers across unrelated scenarios. Stronger for Opus 4.7 by 5%, with one exception: this prompting strategy does not provide a delta between SPX and MSCI EM recommendations, which may point to similar weighting of these markets in the β_C prior.
The instinct is to treat this as a prompt-engineering problem: use a better template, fix the wording, and the issue is contained. But these results suggest something harder. The problem is not only that one prompt was poorly written; it is that nearby prompts can behave as if they are not nearby at all. A committee note, a risk memo, an order swap, and a prior-knowledge sentence are small changes to a human reader. To the model, they can activate different regions of its learned representation space.
We are not claiming to recover the model’s internal geometry. The point is operational. If two prompts are economically equivalent to a human reader but produce different recommendations, then the recommendation function is locally irregular in the space that matters to an investor. Whether the source is token geometry, learned priors, instruction-following heuristics, or decoding dynamics, the portfolio implication is the same: the prompt carries exposure.
That is the constructive point. The prompt’s hidden beta is not obvious, but it is testable. A prompt is not a neutral container for information; it is part of the model specification. Before the output becomes a feature, the local prompt response surface has to be explored, to gain at least an intuition on its expected behavior, and therefore be “hedged” on a posteriori trading decisions.
At Hafnium, this is exactly the reason we go beyond the surface output of models and study the internal sensitivities that drive them: prompt dependence, contextual bias, latent factor exposures, and the stability of recommendations across architectures and regimes.
References
Chon, S., Kim, J., Kim, J., 2025. Multifaceted Variability in LLM-Driven Stock Recommendations.
Robinson, M., Dey, S., Chiang, T., 2025. Token Embeddings Violate the Manifold Hypothesis.
Sun, Y., Kok, S., 2025. Cognitive Biases in Prompts on LLM Outputs.
Turpin, M. et al., 2023. Language Models Don’t Always Say What They Think.
Vaswani, A. et al., 2017. Attention Is All You Need.